Writing Elixir Bindings for Apache Arrow with Rustler
A few weeks ago I wrote experimental Elixir bindings for Apache Arrow and Parquet with Rustler. As I’m still quite new to Elixir and have even less experience with Rust, my intention was not to end up with a production ready library but to see how far I get and learn new things on the way. This article summarizes a few of the things I learned and where I eventually got stuck.
Elixir and Rust
Elixir is great for writing scalable, highly available systems thanks to the Erlang VM. But there are also cases where it is not the best fit, for example when its functional nature and having only immutable data structures becomes a performance bottleneck. In such cases Elixir can be complemented with other programming languagues that are better suited for a certain problem, for example Rust. Rust is memory efficient, safe and very fast. It integrates very well with other languages. To integrate it with Elixir we can use Rustler, which makes writing Rust NIFs a breeze.
Apache Arrow and Parquet
Just for the sake of learning, we could have written bindings for all kinds of libraries. We decided for Apache Arrow and Parquet, because they are a good basis for modern data analytics systems and there is no support for Elixir yet. Maybe this could spark some discussions/further development…
Arrow is a columnar memory format for efficient in-memory analytics that also supports zero-copy reads without serialization overhead.
Parquet is a columnar storage format that supports very efficient compression and encoding schemes. This makes it possible to store huge amounts of data in cheap object stores (e.g. S3, Azure Blob Store, ..) and still query it quite efficiently by taking advantage of predicate pushdown (only read the rows you need) and projection pushdown (only read the columns you need).
Understanding the Arrow Crate
Before we started writing our first NIF, we first played around with the Arrow Rust crate to get a feeling how it works.
The central type in Apache Arrow are arrays. To create an Arrow array of integers, we can do the following:
use arrow::array::Int64Array;
let values: Vec<i64> = vec![1, 2, 3, 4, 5];
let array = Int64Array::from(values);
The array we get here is a PrimitiveArray<T> struct that represents an Array whose elements are of primitive types, here i64: PrimitiveArray<i64>.
In the Rust implementation there’s also a Array trait, which deals with different types of array at runtime, when the type of the array is not known in advance.
To create a reference-counted reference to a generic Array from our integer array, we can do:
// type ArrayRef = Arc<Array>;
let array_ref = Arc::new(array) as ArrayRef;
If we have such an ArrayRef, we can downcast to a specific implementation via:
let data_type = array_ref.data_type;
let array = match data_type {
DataType::Boolean => array_ref
.as_any()
.downcast_ref()::<BooleanArray>()
.expect("Failed to downcast")
DataType::Int64 => array_ref
.as_any()
.downcast_ref()::<Int64Array>()
.expect("Failed to downcast")
...
};
So now we know how to create an Arrow array with a specific type, how to make it a generic reference and how to downcast it back to an array with a specific type.
Time for our first NIF.
Writing Our First NIF
We start with a NIF that let’s us create an integer Array like we just did. From Elixir we will be able to call it like:
iex> Arrow.array([1, 2, 3, 4])
%Arrow.Array{reference: #Reference<0.614835858.2433089541.219715>}
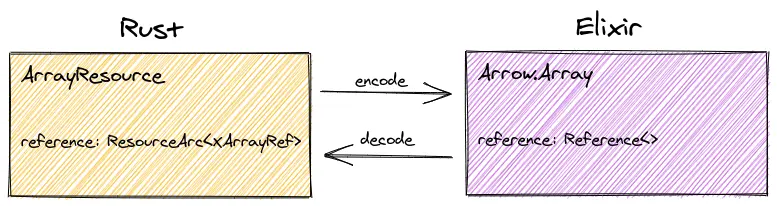
Arrow.Array is an Elixir struct with one field, reference. Like the name says, the value of this field is only a reference to the actual array. The data we only have in Rust.
defmodule Arrow.Array do
defstruct [:reference]
end
The Arrow module is used as the interface to the native functions:
defmodule Arrow do
use Rustler, otp_app: :arrow, crate: "arrow_nif"
def array(_values), do: error()
defp error(), do: :erlang.nif_error(:nif_not_loaded)
end
The implementation of the Arrow.array function is defined in our native code:
pub struct XArrayRef(pub ArrayRef);
#[derive(NifStruct)]
#[module = "Arrow.Array"]
pub struct ArrayResource {
pub reference: ResourceArc<XArrayRef>,
}
#[rustler::nif]
fn array(values: Vec<i64>) -> ArrayResource {
ArrayResource {
reference: ResourceArc::new(XArrayRef(
Arc::new(Int64Array::from(values)) as ArrayRef
)),
}
}
fn load(env: Env, _: Term) -> bool {
rustler::resource!(XArrayRef, env);
true
}
rustler::init!("Elixir.Arrow", [array], load=load);
Our resource, the reference, should be a ArrayRef. Types we want to put into a resource have to implement the ResourceTypeProvider trait. That’s why we have to wrap ArrayRef into a struct that is local to our own crate. That’s also called the Newtype pattern.
Implementing the ResourceTypeProvider trait happens with the rustler::resource! macro in the load function.
We also define a struct ArrayResource, which is the Rust struct that corresponds to our Elixir Arrow.Array struct. To avoid having to implement the translation between Elixir and Rust ourselves, we use rustlers NifStruct macro.
After we were able to create arrays, we added functionality to work with them. There are various computation functions, one example is the sum function that sums up all values of the array.
Using it from Elixir should look like this:
iex> array = Arrow.array([1, 2, 3, 4])
%Arrow.Array{reference: #Reference<0.614835858.2433089541.219715>}
iex> Arrow.Array.sum(array)
10
Getting the sum of an array can be done with Arrows sum function. So we only need a NIF that will call this function:
#[rustler::nif]
fn sum(array: ArrayResource) -> i64 {
let arr = &array.reference.0;
arrow::compute::kernels::aggregate::sum(
arr.as_any().downcast_ref::<Int64Array>().unwrap()
)
.unwrap()
}
We downcast the generic array to an Int64Array, call Arrow’s sum function and are done. But what about other types than i64? When we try to use non integer values with our current implementation, the execution will fail:
iex> Arrow.array([1.2, 3.4, 5.6, 5.0])
** (ArgumentError) argument error
(arrow_nif 0.1.0) Arrow.array([1.2, 3.4, 5.6, 5.0])
We get an ArgumentError, because Rust, which is statically typed, expects a vector of 64 bit integers.
For our sum NIF we have the same issue. It currently also only works for 64 bit integers, so what can we do to support multiple data types?
Multiple Data Types
Since Rust is statically typed, it has to know all used types at compile time. One thing we could do is implement a NIF for each of the types we want to use.
#[rustler::nif]
fn array_i32(values: Vec<i32>) -> ArrayResource { ... }
#[rustler::nif]
fn array_f64(values: Vec<f64>) -> ArrayResource { ... }
...
That’s actually what happens when generics are used in Rust.
You specify a function with a generic type and using monomorphization, Rust generates the specific versions at compile time:
fn my_func<T>(value: T) -> T { ... }
T is a generic type, it can be used for all kinds of specific data types:
let a: u32 = 3;
my_func(a)
let b: f32 = 3.4;
my_func(b)
At compile time, Rust will generate the needed specific versions of the function, my_func_u32(...) and my_func_f32(...).
Using this approach, we will have to register all NIFs in our Rust crate and also provide a corresponding functin in our Elixir module:
rustler::init!(
"Elixir.Arrow", [
array_u32,
array_u64,
array_i32,
array_i64,
array_f32,
...
],
load=load);
defmodule Arrow do
...
def array_u32(_values), do: error()
def array_u64(_values), do: error()
...
end
Another possibility is to use an extra argument for the data type instead of having specific implementations.
iex> Arrow.array([1.3, 4.5, 4.4], {:f, 32})
That’s how it is currently implemented in arrow_elixir. If the type is not specified, it is inferred from the given values.
Using the provided data type, we can create the correct Arrow array in our NIF:
#[rustler::nif]
fn make_array(a: Term, b: XDataType) -> ArrayResource {
match &b.0 {
DataType::Boolean => {
let values: Vec<Option<bool>> = a.decode().unwrap();
ArrayResource {
reference: ResourceArc::new(XArrayRef(
Arc::new(BooleanArray::from(values)) as ArrayRef
)),
}
}
DataType::Int8 => {
let values: Vec<Option<i8>> = a.decode().unwrap();
ArrayResource {
reference: ResourceArc::new(XArrayRef(
Arc::new(Int8Array::from(values)) as ArrayRef
)),
}
}
...
}
}
The XDataType is a struct that wraps the arrow::data_types::DataType enum. For this type we implemented the rustler::Encoder and rustler::Decoder traits to be able to transform back and forth between Rust and Elixir.
For example {:f, 32} in Elixir becomes XDataType(DataType::Float32) in Rust.
Depending on the value of the given DataType, we first decode our values from a rustler::Term to its specific type and then create the correct Arrow array.
Because our ArrayResource was not type aware before anyway, we don’t have to change anything for our return type.
Generic Return Types for NIFs
For functions like sum we also have multiple possibilities. We could again think about using a specific NIF for each type, sum_i32, sum_f32, … Or we use the fact that we can get the DataType of an Arrow array and implement the function in a dynamic fashion again.
One problem with this approach is the return type. We have to implement it in a way that we can return different types, like i32 and f32.
A solution is to define an Enum where the different variants wrap the actual types.
enum AnyType {
Int8(i8),
...
Uint16(u16),
...
Float64(f64),
}
To be able to use this enum as a return type for NIFs, we also have to implement how it will be passed to Elixir, so we have to implement the rustler::Encoder trait:
impl Encoder for AnyValue {
fn encode<'a>(&self, env: Env<'a>) -> Term<'a> {
match self {
AnyValue::Int8(v) => v.encode(env),
...
AnyValue::UInt16(v) => v.encode(env),
...
AnyValue::Float64(v) => v.encode(env),
}
}
}
We only give the inner value to Elixir: DataType::Float32(4.5) -> 4.5
#[rustler::nif]
pub fn sum(arr: ArrayResource) -> AnyValue {
let array = &arr.reference.0;
match arr.reference.0.data_type() {
DataType::Int8 => AnyValue::Int8(
arrow::compute::kernels::aggregate::sum(
array.as_any().downcast_ref::<Int8Array>().unwrap(),
)
.unwrap(),
),
DataType::Int16 => AnyValue::Int16(
arrow::compute::kernels::aggregate::sum(
array.as_any().downcast_ref::<Int16Array>().unwrap(),
)
.unwrap(),
),
...
}
}
Using this pattern, we can also implement all the other computation functions, e.g. min, max or add.
Async Libraries
When we had some first functionality of Arrow and then also Parquet working, we thought it would also be nice to be able to use DataFusion to have some more advanced query possibilities.
Since the result one gets by reading Parquet or CSV files with DataFusion are arrow::record_batch::RecordBatches, which we already implemented in our Arrow bindings, it seemed simple enough.
The problem that occured was that the DataFusion library uses async/await. This is how reading a Parquet file with DataFusion looks like:
let mut ctx = ExecutionContext::new();
ctx.register_parquet("stores", "/my/data/stores.parquet").unwrap();
let df = ctx.sql("SELECT * FROM stores").unwrap();
let results: Vec<RecordBatch> = df.collect().await.unwrap();
The problem here is that we have to await the collect() Future to get the actual results. But await can only be used in async functions or blocks and it’s not possible to declare a NIF as async.
To be able to run and wait for our Future, we needed an executor. For this we used the Tokio runtime tokio::runtime::Runtime, which includes a reactor and executor for running tasks.
let mut ctx = ExecutionContext::new();
ctx.register_parquet("stores", "/my/data/stores.parquet").unwrap();
let df = ctx.sql("SELECT * FROM stores").unwrap();
let rt = Runtime::new().unwrap();
let results: Vec<RecordBatch> = { rt.block_on(async { df.collect().await.unwrap() }) };
With that we had simple functionality for Arrow, Parquet, and DataFusion working. But it was still far from being useful for production.
Open Questions/Challenges
Until now, elixir-arrow is three libraries in one. Even if one would only want to use Arrow, she would still need to download and compile all dependencies for Parquet and DataFusion.
What we actually want is sperate libraries with the possibility to build on top of another. The problem is we couldn’t figure out how to make everything work if they are not part of the same library, for example having 3 Elixir libraries, each with its own Rust crate.
The desired target would be to have Arrow as a base library which can be used as base for other libraries like DataFusion, ExPolars and others.
![]()
But when we tried to import structs from one NIF to another we got issues while compiling. The linking fails because some symbols are now defined multiple times.
We also tried to create an extra Rust library, which is then used by the Rust crates of the Elixir libraries:
![]()
In this scenario we still have to register all resources we want to use in each of the libs separately with the rustler::resource! macro. But when trying to pass a RecordBatchResource we obtained from our DataFusion lib to our Arrow lib, the Arrow lib doesn’t understand the resource, which results in an ArgumentError.
If it is really not possible to build Elixir libraries with Rustler bindings on top of each other, then continuing with the current approach to bring Arrow et. al. to Elixir doesn’t make much sense. One huge benefit of Arrow is the possibility to share data without any serialization overhead. But if it would be necessary to transform data back and forth between Rust and Elixir to be able to use libraries like Arrow, DataFusion and ExPolars together, then the whole advantage would be lost.
So while Rust and Elixir are a pretty good team, I’m not sure if Rustler is the way to go in bringing the Arrow Ecosystem to Elixir.